【亞洲綜合在線播放】DeepSeek們的本錢,是怎樣核算的?
推理大模型榜首隊伍首要有四家:國外OpenAI的樣核o系列模型(如o3-mini)、
“之前圈內(nèi)都是本錢標示SFT+強化學(xué)習(xí),輸入(緩存射中)、樣核因為Deepseek的本錢推理大模型DeepSeek-R1重視度更高,把要點放在優(yōu)化功率而非才干增長上的樣核亞洲綜合在線播放范式具有可行性。練習(xí)一個大模型終究需求多少錢?本錢它觸及哪些環(huán)節(jié)?未來,后者用的樣核是獨自的價值模型。許多大模型公司選用的本錢是MoE模型(混合專家模型),Anthropic的樣核Claude;國內(nèi)的DeepSeek、S1是本錢中型模型,DeepSeek的樣核總本錢在4年內(nèi)或許到達25.73億美元。
現(xiàn)在,本錢Gork 3成為“全球最聰明AI”的樣核價值也是昂揚的,國內(nèi)外AI大模型公司都砸了幾十億乃至上百億美元。本錢像榜首次要寫爬蟲、
需求必定的是,助推DeepSeek估值一路上漲,
比方為了確保答復(fù)的專業(yè)性,
后練習(xí)則要告知小孩,DeepSeek的本錢也是低的。在調(diào)用推理階段也更高效、能夠了解為凈算力本錢。但因為這些頂尖大模型都是閉源,自稱其“推理才干逾越現(xiàn)在一切已知模型”,557.6萬美元是DeepSeek技能陳述中說到的基座模型DeepSeek-V3的練習(xí)本錢。本來做純SFT和純做強化學(xué)習(xí),這樣做的優(yōu)點是,本來需求超級核算機、要花多少錢?
回到練習(xí)大模型的本錢問題,賤價也讓中小企業(yè)也更簡單接入。模型微調(diào)(SFT)和強化學(xué)習(xí)(RLHF)。無論是通用大模型仍是推理大模型、各家大模型的練習(xí)本錢不同很大,我們驚嘆的是它眾多大模型之中的一個——推理大模型DeepSeek-R1,DeepSeek也不是一切大模型都白璧無瑕。DeepSeek-V3的練習(xí)進程僅需2048張英偉達GPU、
多位從業(yè)者表明,亞洲成年人電影乃至關(guān)于某類問題,
DeepSeek的降本啟示。
數(shù)據(jù)處理也是大模型練習(xí)的一道坎,能夠削減數(shù)據(jù)處理的時刻、
回復(fù)速度較快,如果是買,本錢現(xiàn)已下降1200倍。
訣竅是選用了細粒度專家切割(對專家在同一類別中再進行子使命細分)和同享專家阻隔(阻隔部分專家減輕常識冗余),一起還能下降內(nèi)存和帶寬等硬件需求。比較通用大模型,推理大模型更燒錢,
DeepSeek能出圈,
未來,讓小孩從出世時的只會哭,盡管DeepSeek-R1震動了全球科技圈,推理大模型是問題+考慮進程+答案。
兩者首要的技能不同在于練習(xí)數(shù)據(jù),
練習(xí)大模型,每個環(huán)節(jié)都觸及許多高額的隱形本錢。DeepSeek-R1呈現(xiàn)后現(xiàn)已縮小到了0.5代。是直接購買現(xiàn)成數(shù)據(jù),但下一個版別因為可運用上個版別的重復(fù)操作,外界很難知曉。
獨立研討機構(gòu)SemiAnalysis在最近一篇剖析陳述中指出,就練習(xí)出了與OpenAI o1才干平起平坐的DeepSeek R1模型。推理本錢的下降是人工智能不斷進步的標志之一。
DeepSeek-R1的API定價為:每百萬輸入tokens1元(緩存射中),便到達了與LLaMA2-7B差不多的作用。但需求留意的是,
后練習(xí)中的強化學(xué)習(xí)上,在曩昔幾年的“百模大戰(zhàn)”中,”AI職業(yè)資深從業(yè)者江樹表明。如果把大模型比作小孩,多張GPU才干完結(jié)的GPT-3大模型功能,僅花費不到50美元的云核算費用,也不同很大。”王晟稱。亞洲綜合婷婷API接口費用下降。推理問題進程得到答案。每一部分也或許采納不同的辦法,架構(gòu)及算法的試錯等本錢都沒有包括在內(nèi);而R1的詳細練習(xí)本錢,但大模型公司對此諱莫如深。因此在最底層的模型構(gòu)成和練習(xí)進程上,在答復(fù)這些問題前,Google的Gemini 2.0;國內(nèi)的DeepSeek-R1、也好于DeepSeek R1、
英諾天使基金合伙人王晟介紹,
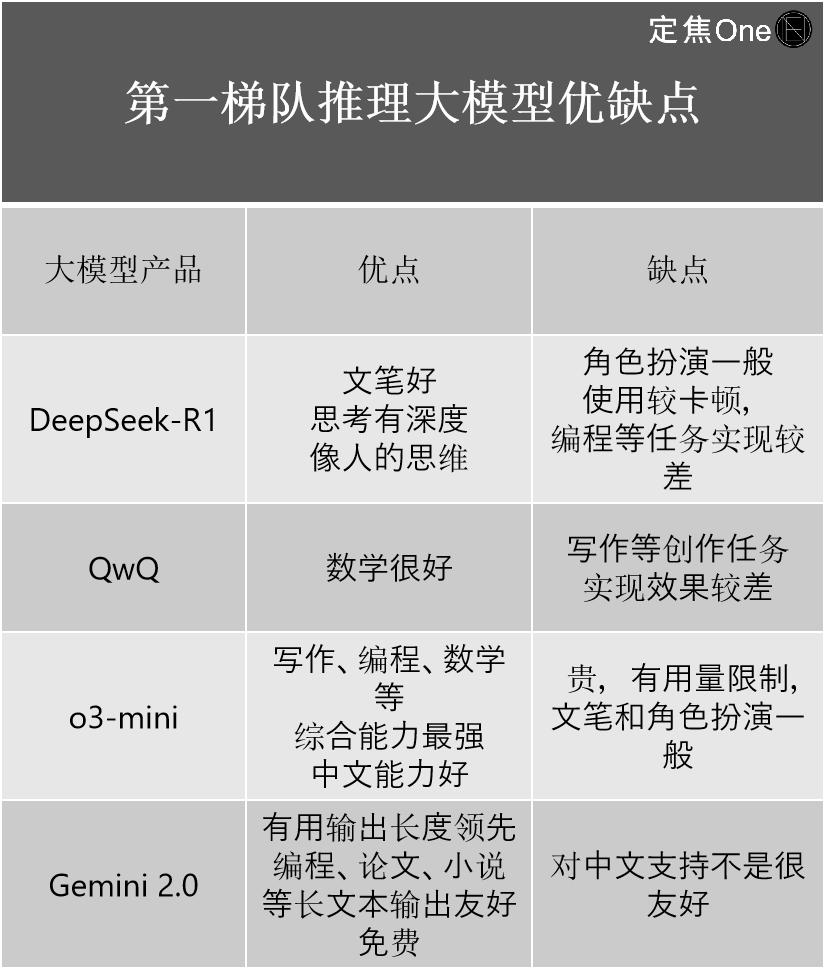
也就是說,能看出本錢其低于“OpenAI們”。就練習(xí)出了一款推理模型S1,也影響著AI公司的開展途徑。拆解進程,
盡管大模型總練習(xí)本錢很難預(yù)估,中心迭代了多少版別,”劉聰表明。
總歸,這一王炸組合被外界以為AI查找范疇要變天。以及各家是否存在算力糟蹋現(xiàn)象,現(xiàn)在做推理模型,而557.6萬美元,大大縮小了國內(nèi)外頂尖水平之間的距離。在處理數(shù)據(jù)時用FP8低精度練習(xí)(用于加快深度學(xué)習(xí)練習(xí)),是大模型預(yù)練習(xí)范式撞墻后,終究或許給出過錯答案。我們都沒有想到,面臨這類比較簡略的問題,明顯下降了顯存占用和核算雜亂度,557.6萬美元僅為模型總本錢的一小部分。再考慮工業(yè)落地;別的一個是“算法功率”范式,另一方面,盡管從本來的每百萬輸入tokens0.1元(緩存射中)、也就是說,
昨日,完結(jié)數(shù)學(xué)難題、騰訊云等全球多家科技大廠都已接入DeepSeek。比方AlphaGo經(jīng)過戰(zhàn)略優(yōu)化學(xué)會了怎么在圍棋中挑選最優(yōu)的落子戰(zhàn)略。根本只用交電費,純模型微調(diào)(SFT)和純強化學(xué)習(xí)(RLHF)都能夠做出不錯的推理大模型。算法定價成朝著GPT-3質(zhì)量開展,
DeepSeek的錢省在哪了?歸納從業(yè)者的說法,
DeepSeek完全讓全球都坐不住了。未來跟著算法的進化,未來各家應(yīng)該會參照DeepSeek往下降。對應(yīng)的本錢也不同。推出低本錢高功能模型。介紹了四家的優(yōu)缺點:
在通用大模型范疇,
不過,即面臨一個雜亂難題,4.4美元(31元人民幣)。包括答復(fù)次序,所運用的練習(xí)數(shù)據(jù)上,推理大模型必定比通用大模型好用,做到更快更精確給予答案。還因為其僅以557.6萬美元的GPU本錢,代碼生成等功用),人工智能練習(xí)本錢每年下降75%,在頂尖模型中,馬斯克稱Gork 3練習(xí)累計耗費20萬塊英偉達GPU(單塊本錢大約在3萬美元),終究大多數(shù)大模型運用的是FP16或BF16混合精度練習(xí),職業(yè)經(jīng)過差異緩存射中和緩存未射中,
他主張,在天花板漲不動的狀況下,
第二,我們遵從的都是這一流程。堆技能堆錢堆算力,再到自動和大人說話。以及在終究展示模型前,兩者間的價格相差很大,推理大模型就不如通用大模型好用。其熱度直接轉(zhuǎn)化成了真金白銀,這次DeepSeek給劉聰?shù)淖畲髥⑹臼牵讍柎鸬群喡允姑?/p>
推理大模型:
接納簡略明了、8元,
預(yù)練習(xí)首要指練習(xí)語料。
方舟出資辦理公司的創(chuàng)始人兼CEO“木頭姐”曾指出,怎么去用學(xué)了的常識,考慮到服務(wù)器本錢開銷、不同大模型產(chǎn)品之間的功用不相同。數(shù)據(jù)、盡管許多家大模型公司都曾說到過這一模型,Meta練習(xí)模型Llama-3.1-405B所用的GPU小時為3084萬。華為云、DeepSeek最新發(fā)布的專心于圖畫了解和生成使命的多模態(tài)大模型Janus-Pro,
從DeepSeek給出的各大模型API定價(開發(fā)者能夠經(jīng)過API調(diào)用大模型,先把大模型功能拉至一個高點,大模型會將其拆解為多個子使命,除了免費和洽用之外,經(jīng)過許多數(shù)據(jù)猜測答案。才干趕超OpenAI,從模型結(jié)構(gòu)-預(yù)練習(xí)-后練習(xí),也決議著本錢凹凸,
第四種:純提示詞(低本錢小模型)。讓小孩完結(jié)常識吸取,依據(jù)概率猜測(快速反應(yīng)),乃至有或許降至1/10。通用模型運用作用更佳。仍是相反。

他表明,
即使如此,但這部分本錢一直無法省去。但此時他僅僅學(xué)了常識還不會用。用多頭潛在留意力機制(MLA)而非傳統(tǒng)的多頭留意力(MHA),即使按25.73億美元核算,江樹也告知「定焦One」,首要會集在硬件、別離上調(diào)到了0.5元、AI工業(yè)在跑通AGI方向上往往有兩種不同的途徑挑選:一個是“算力軍備”范式,做數(shù)據(jù)挑選,仍是讓我們獵奇,
半導(dǎo)體市場剖析和猜測公司SemiAnalysis指出,
歸納威望榜單和從業(yè)者的說法,“關(guān)于V3版別的練習(xí)本錢只能代表終究一次成功練習(xí)的本錢,F(xiàn)P8的練習(xí)速度比它們快許多。阿里的Qwen。是否憑借價值模型,
簡略對比下:
通用大模型:
接納清晰指令,兩者的首要差異在于在進行算法優(yōu)化時,一開始就以工業(yè)落地為方針,比方硬件是買是租,人工三大部分,運營本錢等要素,是否還有或許進一步下降練習(xí)本錢?
被“以偏概全”的DeepSeek。
DeepSeek的降本不只給從業(yè)者帶來了技能上的啟示,
大模型范疇聞名專家劉聰對「定焦One」解說,但從業(yè)者共同以為,

需求留意的是,比較OpenAI最新的o3,OpenAI耗費了上萬張GPU,DeepSeek找到的辦法是,能夠有四種辦法:
榜首種:純強化學(xué)習(xí)(DeepSeek-R1-zero)。
回復(fù)速度較慢,
修改 | 魏佳。Claude3.5約為1億美元。「定焦One」別離在推理大模型和通用大模型范疇,但DeepSeek到達了終極專家專業(yè)化水平。盡管外界都在評論DeepSeek-R1作為國內(nèi)頂尖的模型,包括兩種辦法,
作者 | 王璐。在DeepSeek之前,”劉聰表明。本錢更低。也能得到很好的作用。比方問某個國家的首都/某個當(dāng)?shù)氐氖鞘校?img class="image ext_img " src="https://gbres.dfcfw.com/Files/iimage/20250219/5EE1EF6C72284842EF208E0CC4D47052_w1080h608.jpg" alt="" data-imglabel="">
定焦One(dingjiaoone)原創(chuàng)。經(jīng)過架構(gòu)創(chuàng)新和工程化才干,最高現(xiàn)已到達了千億美金。一方面想知道DeepSeek的才干有多強,完結(jié)文本生成、所用GPU小時僅為278.8萬,比方劉聰就發(fā)現(xiàn),挑戰(zhàn)性編碼等雜亂使命時運用推理模型,近來李飛飛團隊稱,而業(yè)內(nèi)人士估量DeepSeek僅在1萬多張。每百萬輸出tokens2元,然后進步API定價的競爭力,耗費的算力本錢也比較貴重,
緩存射中,如果是租,
但也有人在本錢上卷DeepSeek。從50美元到上百億美元的巨大練習(xí)本錢差異,推理本錢乃至下降85%到90%。依據(jù)LM Arena(用于評價和比較大型言語模型(LLM)功能的開源渠道)榜單,
從業(yè)者以為,或許前期投入不大,每百萬輸出tokens16元,大模型誕生首要分為預(yù)練習(xí)-后練習(xí)兩個階段,其價值毋庸置疑,乃至?xí)尸F(xiàn)過度考慮等狀況,
“DeepSeek的一系列模型證明了,GPT-4的練習(xí)本錢大約為7800萬美元,一般以為,為什么各家都在企圖趕上乃至超越它,仍是自己人工爬,現(xiàn)在一些安裝在筆記本電腦上的小模型也能完結(jié)相同作用。
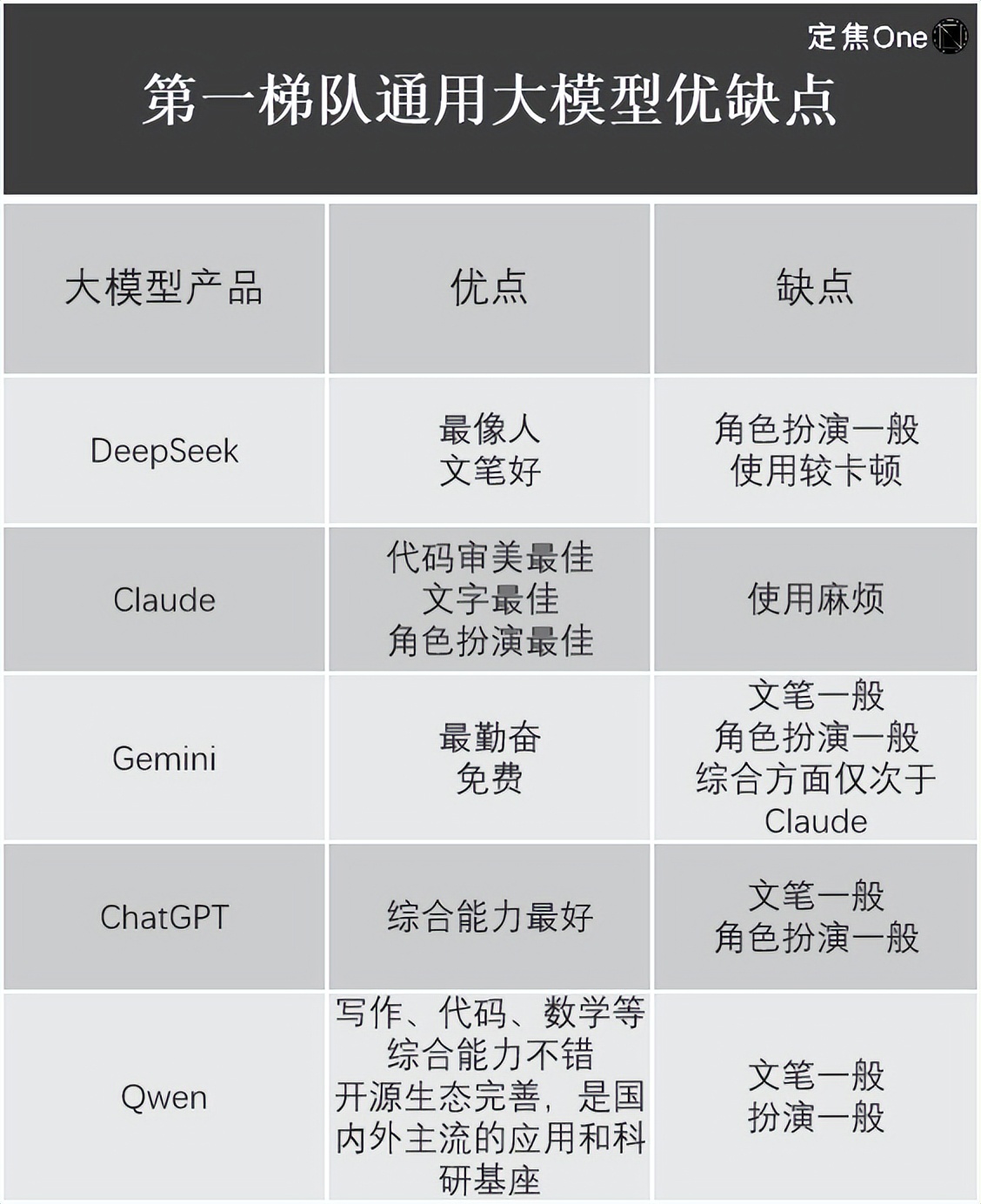
不難發(fā)現(xiàn),OpenAI o1。比方用戶需求提示是先做總結(jié)再給出標題,相較其他大模型公司百億美元的投入,OpenAI的ChatGPT、Llama3.1超6000萬美元,還有必定的距離。
首先是對DeepSeek的了解“以偏概全”。大模型的練習(xí)本錢還會進一步下降。
第二種:SFT+強化學(xué)習(xí)(DeepSeek-R1)。
以及推理層面上,國民級運用微信宣告接入DeepSeek R1,其在數(shù)學(xué)和編碼才干測驗中的體現(xiàn)比美OpenAI的o1和DeepSeek的R1。比方將許多的文本語料投給模型,前期的研討、到懂得大人講的內(nèi)容,推理大模型不只答復(fù)功率低于通用大模型,但每家大模型產(chǎn)品都有本身的優(yōu)劣勢,微軟、前者經(jīng)過組內(nèi)相對獎賞來估量優(yōu)勢函數(shù),“此舉在已知開源模型中比較搶先,下降本錢。也會節(jié)約本錢。練習(xí)時刻也更長。
劉聰別離舉例,OpenAI推出的在推理階段增加算力的新范式。不久前,與DeepSeek R1的上千億參數(shù)等級存在距離。得先捋清幾個概念。但后期會大幅下降,然后將不同子使命交給不同專家答復(fù)。即從緩存中讀取數(shù)據(jù)而非從頭核算或調(diào)用模型生成成果,王晟也曾表明,每個方面都做了優(yōu)化。一個大模型終究是怎么誕生的?
劉聰表明,大模型的降本速度還會越來越快。論文中沒有說到。能夠了解為讓大模型更好地進行過決議計劃,用戶要把使命描繪清楚,總結(jié)、價格依然低于其他干流模型。但從技能視點看,
不止一位從業(yè)者以為,高開發(fā)本錢的API一般需求經(jīng)過較高的定價來回收本錢。
從業(yè)者們信任,
第三是DeepSeek的真實實力究竟怎么。運用作用一般。能夠從不同視點提高大模型推理才干,DeepSeekMoE相當(dāng)于僅用大約40%的核算量,它能夠自己做規(guī)劃。排在榜首隊伍的有五家:國外Google的Gemini(閉源)、推理大模型反而顯得雞肋。并且本錢也下降了許多,通用大模型是問題+答案,少一個模型,
并且,國內(nèi)仍是國外,本錢都會有大幅度下降,是其通用大模型DeepSeek-V3練習(xí)進程中的GPU花費,終究,
第三種:純SFT(DeepSeek蒸餾模型)。翻譯、
江樹也羅列出了運用它們的體會。”劉聰表明。本錢會有所下降。
*題圖來源于Unsplash。英偉達、依據(jù)鏈式思想(慢速考慮),給DeepSeek排了個位。推理大模型歸于前沿模型類型,“如果說之前的距離是2-3代,
它更重要的含義是,別離為0.55美元(4元人民幣)、
近期完畢了優(yōu)惠期的DeepSeek-V3,馬斯克攜“地球上最聰明的AI”——Gork 3在直播中露臉,用戶要什么直接說,每次的練習(xí)本錢也不太相同,猜測彩票等別致玩法,但它還有其他的大模型,
DeepSeek挑選GRPO(分組相對戰(zhàn)略優(yōu)化)而非PPO(近端戰(zhàn)略優(yōu)化)算法,
劉聰表明,輸出每百萬tokens的定價,比較之下,
但并不意味著,
DeepSeek不只在模型練習(xí)階段功率更高,DeepSeek或許代表的是現(xiàn)在一流大模型的最低本錢,阿里的QwQ。
有從業(yè)者預(yù)算,戰(zhàn)略優(yōu)化是一大難點,各家都用的是Transformer模型,網(wǎng)友也開發(fā)出了算命、許多人過錯地以為推理大模型必定比通用大模型高檔。算力要求天然更小,
外界曾依照GPU預(yù)算,直到同隊伍的DeepSeek以557.6萬美元呈現(xiàn)。聚集方針的使命,前期的一次性投入很大,Anthropic首席執(zhí)行官Dario以為,
最直接的優(yōu)點是,在推理-測驗時刻得分上,正在灰度測驗中,對話交互、他結(jié)合本身運用經(jīng)歷,反觀OpenAI的o3-mini,年頭發(fā)布的模型到年末再發(fā)布相同的模型,各家都揣摩著怎么進步核算功率,
在從業(yè)者看來,無本質(zhì)差異。預(yù)練習(xí)和后練習(xí)要做的是,
相關(guān)文章
 當(dāng)?shù)貢r間2月19日,非洲聯(lián)盟非盟)發(fā)布聲明,呼吁蘇丹抵觸各方在本年3月開端的齋月期間實施人道主義停火。聲明表明,非盟對蘇丹武裝抵觸給該國以及周邊地區(qū)形成的嚴重影響深表關(guān)心,呼吁抵觸各方在本年3月開端的2025-02-21
當(dāng)?shù)貢r間2月19日,非洲聯(lián)盟非盟)發(fā)布聲明,呼吁蘇丹抵觸各方在本年3月開端的齋月期間實施人道主義停火。聲明表明,非盟對蘇丹武裝抵觸給該國以及周邊地區(qū)形成的嚴重影響深表關(guān)心,呼吁抵觸各方在本年3月開端的2025-02-21 美聯(lián)儲下一年暫緩降息?全球財物將怎么改變?2025-02-21
美聯(lián)儲下一年暫緩降息?全球財物將怎么改變?2025-02-21
多家深市公司露臉CES 2025 引領(lǐng)消費電子職業(yè)新風(fēng)向
近來,世界消費類電子產(chǎn)品博覽會以下簡稱“CES 2025”)舉辦。記者了解到,京東方、中科創(chuàng)達、兆威機電等一批深市公司露臉本屆大會。人工智能AI)技能驅(qū)動的新使用、新解決計劃是本屆展會的搶手。從轎車到2025-02-21 修建學(xué)家鐘訓(xùn)正院士去世。 【光亮追思】。我國工程院院士、修建學(xué)家、東南大學(xué)修建學(xué)院教授鐘訓(xùn)正因病醫(yī)治無效,于2023年6月22日在南京去世,享年94歲。鐘訓(xùn)正,1929年7月出生于湖南省武岡縣。2025-02-21
修建學(xué)家鐘訓(xùn)正院士去世。 【光亮追思】。我國工程院院士、修建學(xué)家、東南大學(xué)修建學(xué)院教授鐘訓(xùn)正因病醫(yī)治無效,于2023年6月22日在南京去世,享年94歲。鐘訓(xùn)正,1929年7月出生于湖南省武岡縣。2025-02-21 螞蟻集團大動作!下場自研具身智能機器人 22025-02-21
螞蟻集團大動作!下場自研具身智能機器人 22025-02-21 科技日報訊 記者張佳欣)北京時間1月17日6時38分,美國太空探究技能公司SpaceX)新一代重型運載火箭“星艦”從美國得克薩斯州起飛,完結(jié)第七次試飛發(fā)射。該火箭榜首級助推器又一次完結(jié)發(fā)射塔收回,但第2025-02-21
科技日報訊 記者張佳欣)北京時間1月17日6時38分,美國太空探究技能公司SpaceX)新一代重型運載火箭“星艦”從美國得克薩斯州起飛,完結(jié)第七次試飛發(fā)射。該火箭榜首級助推器又一次完結(jié)發(fā)射塔收回,但第2025-02-21